HTTP and JSON
Example: A Smart Home System
Let's first look at an example system. Two weeks ago you learned how to connect the Sense HAT and the Raspberry Pi to a Python program, so that you could read values from the Sense HAT and also turn on its LEDs. Imagine now that this Raspberry Pi is part of a system you want to install at home, for instance to check the temperature while you are away, and maybe switch on the heater before you arrive home. The sensors report their values to a server. Since this server is somewhere in a data center, we say that it's running in the cloud. The sensors report their values periodically to the server, and the server keeps track of the values sent. When we want to know the temperature at home, we can simply ask the web server with a browser to present us the last measured temperature value.
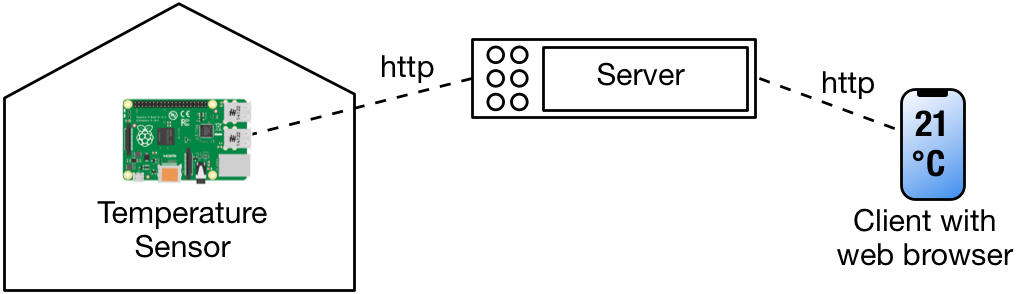
During this week, we want to implement such a system, with the Raspberry Pi and Sense HAT as our sensor, and another Raspberry Pi as the web server. For this, we need several elements:
- We need to know more about the WWW and the HTTP protocol.
- We need to transform data so we can send it.
- We need to build a web server in Python.
Think a bit: What can be some benefits of using HTTP, a web server and a browser as elements in this system?
Sequence Diagrams and Message Patterns
From today on we start to think a bit more about the patterns of interactions between computers, that is, in which sequence they send messages between each other. For that, we use a special type of diagram, called sequence diagram. Below you see a very simple one. The vertical lines (top to bottom) are called lifelines and define a computer or any other communicating element. The box at the start of the lifeline describes what the lifeline represents. Here, we just apply role names, and call one of them sender and the other one receiver. The horizontal arrow represents a message that travels between the computers.

Messages can be lost, for instance when somebody plugs out a cable, disturbs the wireless signal or when some part of the network in between fails. We can show that a message is lost by letting it run into a big cross:
The above interaction follows a simple patternthat we call single message. As you can see, a problem with this message pattern is that messages can get lost, and neither the sender nor the receiver detect it. For that reason, we often use other message patterns or build applications so that they can handle message losses. The next pattern we are going to look at is already an improvement.
The Request-Response Message Pattern
Another message pattern is request-response, shown in the diagram below. It is used when one computer (the requestor) wants to get some information from another one (the responder).

Another benefit of the request-response pattern is that the requestor knows that the responder has received the request once it receives the response. Therefore, we often use a request-response pattern even when we are not interested in the content of the response, just to be sure that the original request has ben sent. The response in this case is also called acknowledgement, and the entire pattern is called a handshake. In case the requestor does not receive a response within some time, it can for instance try again and send another request. To sum up, the request-response pattern is used in two cases:
-
When the requestor needs some data from the responder, i.e., when the requestor wants to know something.
-
When the requestor only wants to tell something to the responder, but wants to know of the responder actually received the data.
WWW -- The World Wide Web
Many people do not distinguish between the Internet and the World Wide Web. The two are, however, quite different: The Internet, as you have learned by now, is a system of interconnected computer networks that communicate via IP and enable services like email, video streaming, or internet telephony. It also enables the World Wide Web, which is a collection of documents that you can access from specific servers.
The Client-Server Model
When you access a website, this involves an interaction between two computers: The web server that stores the website, and your computer with a web browser that acts as a client.

Both the client and the server are computers, but within this interaction model they behave quite different: The server doesn't know anything about the clients before they connect, and just waits for clients. Once a client makes a request, it answers this request with a response. The server serves the request. In the basic case of serving a website, the server only reacts on the requests. All interactions are initiated (started) by the client.
Often, servers are powerful machines, running in a data center and serving many clients. But that is not always the case. A server can also be a tiny computer, serving only a single or a few other clients. The term client-server only refers to the roles they have in the interactions: the client takes initiative and the server responds.
HTTP
Once two computers communicate, we have to ensure that they understand each other. This is where protocols come in. They define a set of rules that all partners have to follow. You already know something about the Internet Protocol, IP. This protocol defines how we can send data packages between computers connected networks that together make up the Internet. TCP is a protocol that is used to control IP packets, so that they arrive in a particular order and are resubmitted when they get lost.
Sending data packets does not yet ensure that computers can actually understand the data. This is why there are protocols defined on top of TCP and IP, for the different types of applications that we want to use on the internet. For accessing websites, this protocol is HTTP, or Hypertext Transfer Protocol. HTTP is based on a pattern that is called request-response, meaning that all interactions consist of a request message, sent by the client, and a corresponding response, sent by the server. To get a website, the request looks as follows:
GET /index.html HTTP/1.1
Host: www.example.com
Note that the keyword GET shows that the browser would like to access
a resource. It is followed by /index.html, which is the path of the
website we would like to read. The corresponding response can look like
this:[^3]
HTTP/1.1 200 OK
Date: Mon, 23 May 2005 22:38:34 GMT
Content-Type: text/html; charset=UTF-8
Content-Length: 138
Last-Modified: Wed, 08 Jan 2003 23:11:55 GMT
Server: Apache/1.3.3.7 (Unix) (Red-Hat/Linux)
ETag: "3f80f-1b6-3e1cb03b"
Accept-Ranges: bytes
Connection: close
<html>
<head>
<title>An Example Page</title>
</head>
<body>
Hello World, this is a very simple HTML document.
</body>
</html>
The answer indicates the HTTP version, followed by the token 200 OK,
which means that the response actually contains the requested
information. When a site is not accessible, the code is a
404 Not Found, which you may have seen when browsing the web.
Following the header information is the actual content of the document
we want to access. Here, it is a HTML site, beginning with the <html>
tag. This language describes websites with some markup, so that you can
have tables and arrange all sorts of elements and render them in a
browser. So when you request a website, it's basically these two
messages that are exchanged between your browser (the client) and the
web server.
Web Server in Python
It's simple to create a web server in Python.

Of course, much of the code running the server is hidden in libraries, but our code controls some interesting parts of the server.
-
We define a class
RequestHandler. This class has the only task to define how we answer a request. -
When a request comes to the web server, the method
do_GET(self)is called by the server. In this method we can compute our response. In this case, we return response code200(which means OK), set the content type in the header, and then set the content to beHello World. We encode the string into bytes, using Unicodeutf-8encoding. -
These lines start the actual server. We create an instance of the class
HTTPServerand then tell it to start.
Don't worry too much about some of the code here, but focus on the
do_GET() method, which gets called once the request arrives and then
computes an answer.
[^3]: These code snippets are taken from https://en.wikipedia.org/wiki/Hypertext_Transfer_Protocol#HTTP_session_state